
About Hui Wu
I am a Principal Research Scientist and Manager at IBM Research, leading the Model Feedback and Adoption initiative
for IBM’s Granite AI Models, with a focus on enterprise AI applications. Previously,
I led the Edge AI research team, advancing distributed and scalable AI model lifecycles. My research has been published
in machine learning and computer vision venues, including NeurIPS, CVPR, and AAAI. My work in multimodal AI led to the
creation of the Fashion IQ Challenge, an open-dataset competition featured at ICCV 2019 and CVPR 2020. I co-founded the Workshop
on Computer Vision for Fashion, Art, and Design, which was hosted at ECCV 2018, ICCV 2019, and CVPR 2020.
Before joining IBM Research in 2015, I earned my Ph.D. in Computer Science from the University of North Carolina at Charlotte,
where my dissertation focused on machine learning and medical image analysis.
Contact me: wuhu AT us.ibm.com
This site is lightly maintained to reflect my current professional status. Earlier content remains available for reference and background.
Past Research Activities
-
Mar. 2021: Two papers accepted at CVPR 2021.
-
Dec. 2020: Paper "NASTransfer: Analyzing Architecture Transferability in Large Scale Neural Architecture Search" accepted at AAAI 2021.
-
Jun. 2020: We are hosting Fashion IQ challenge at the third workshop on Computer Vision for Fashion, Art and Design
at CVPR 2020. Please see the article at CVPR Daily.
-
Sep. 2019: Drill-down: Interactive Retrieval of Complex Scenes using Natural Language Queries accepted at NeurIPS 2019.
-
Jul. 2019: We are hosting Fashion IQ challenge at ICCV 2019.
-
May. 2019: I am co-chairing the second workshop on Computer Vision for Fashion, Art and Design
at ICCV 2019.
I am also co-chairing Linguistics Meets Image and Video Retrieval Workshop
at ICCV 2019.
- Apr. 2019: Our demo on interactive fashion retrieval accepted at CVPR 2019 demo track.
- Sep. 2018: Dialog Based Interactive Image Retrieval accepted at NeurIPS 2018.
-
Sep. 2018: I was co-chairing the first workshop on Computer Vision for Fashion, Art and Design
at ECCV 2018.
-
Jan. 2018: Worked with fashion designers from Fashion Institute of Technology on exploring computer vision to enhance fashion design process. [Summary Video]
[Women's Wear Daily]
[Town & Country]
Early Research Work
Dialog-based Interactive Image Retrieval
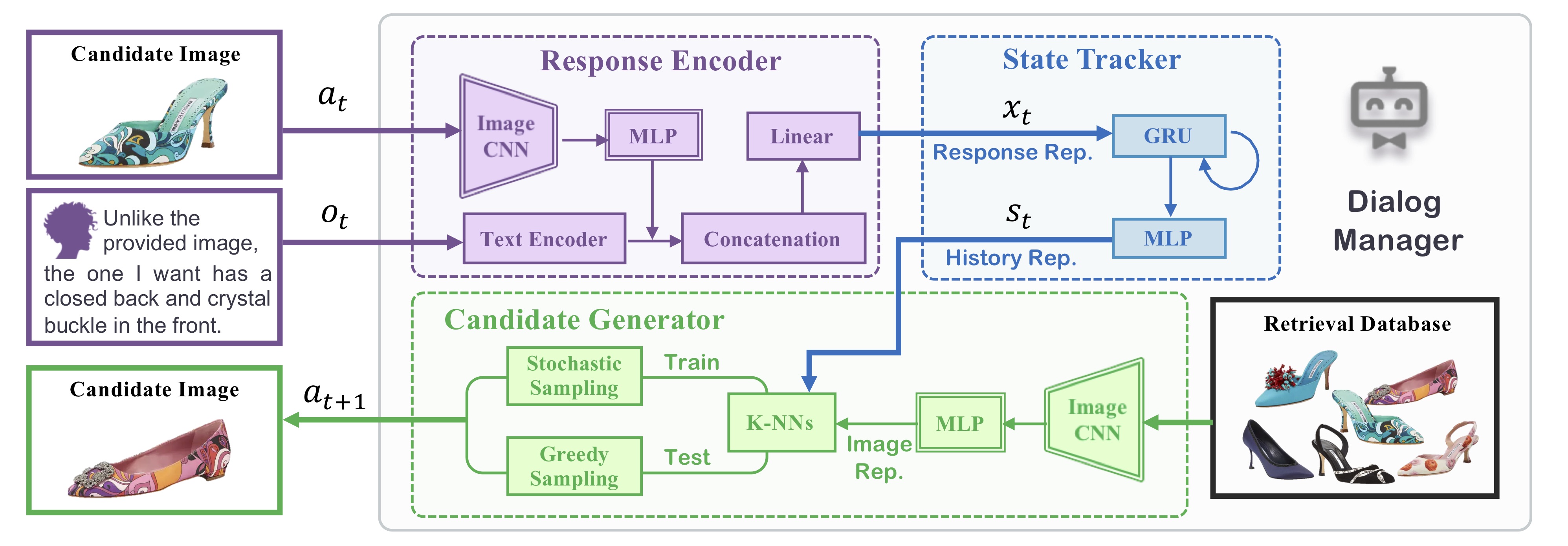 Dialog-based Interactive Image Retrieval
Dialog-based Interactive Image Retrieval
Xiaoxiao Guo*, Hui Wu*, Yu Cheng, Steven J. Rennie, Gerald Tesauro and Rogério S. Feris (* equal contribution)
NeurIPS 2018
[PDF]
[CODE]
[DEMO]
Overview
We proposed a novel type of dialog agent for the task of interactive image retrieval.
Recently, there has been a rapid rise of research interest in visually grounded conversational
agents, driven by the progress of deep learning techniques for both image and natural
language understanding. A few interesting application scenarios have been explored by
recent work, such as collaborative drawing, visual dialog and object guessing game.
In this work, we tested the value of visually grounded dialog agents in a practical and yet
challenging context. Specifially, we proposed a novel framework of image retrieval system which learns to seek
natural and expressive dialog feedbacks from the user and iteratively refine the retrieval result.
Semantic-aware Food Visual Recognition
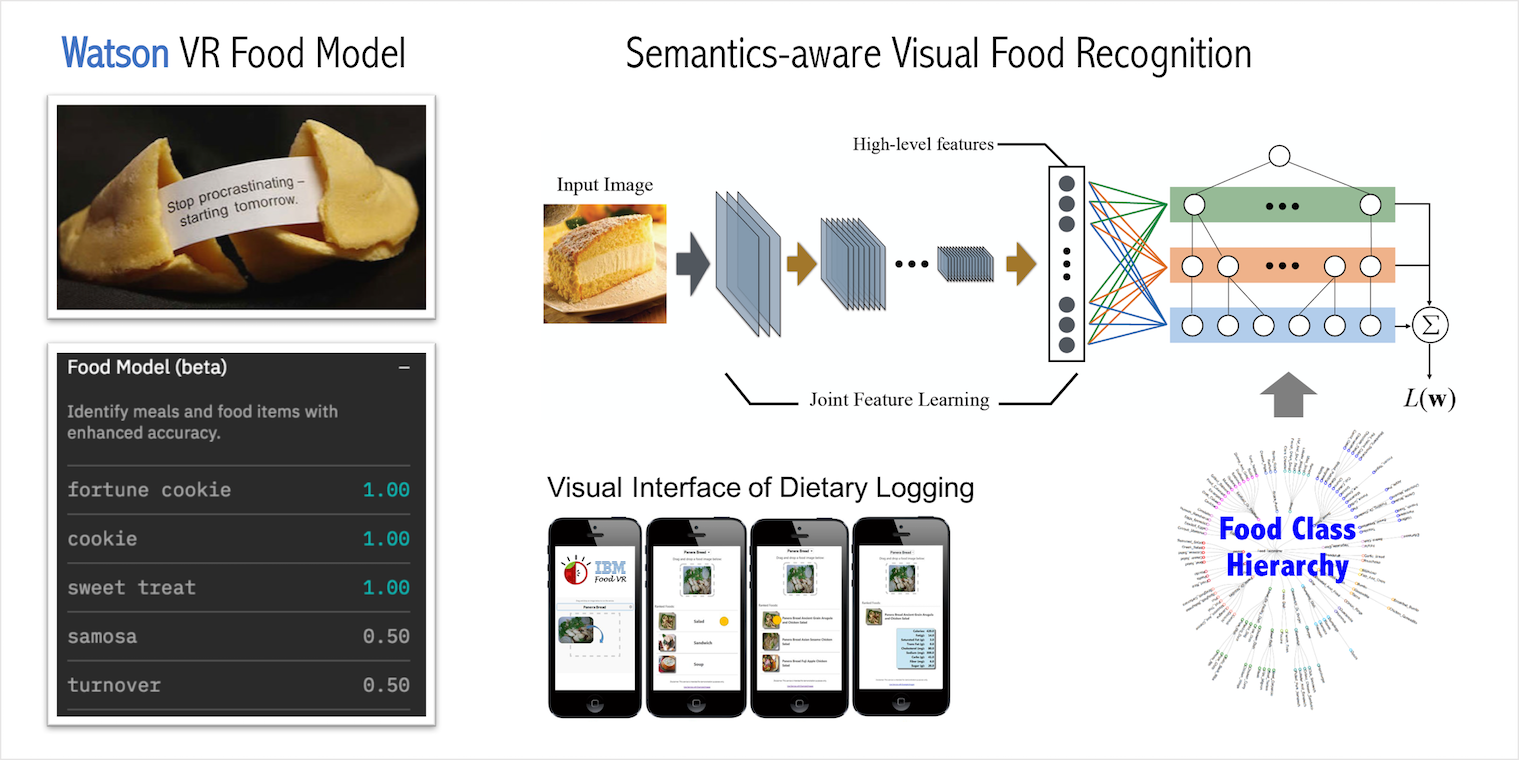 Learning to make better mistakes - Semantics-aware visual food recognition
Learning to make better mistakes - Semantics-aware visual food recognition
Hui Wu, Michele Merler, Rosario Uceda-Sosa and John R. Smith
ACM Multimedia, 2016
[PDF]
[Watson API]
The growing popularity of fitness applications and people’s need for
easy logging of calorie consumption on mobile devices has
made accurate food visual recognition increasingly desireable.
In this project, we proposed a visual food recognition framework that integrates
the semantic relationships among fine-grained food classes.

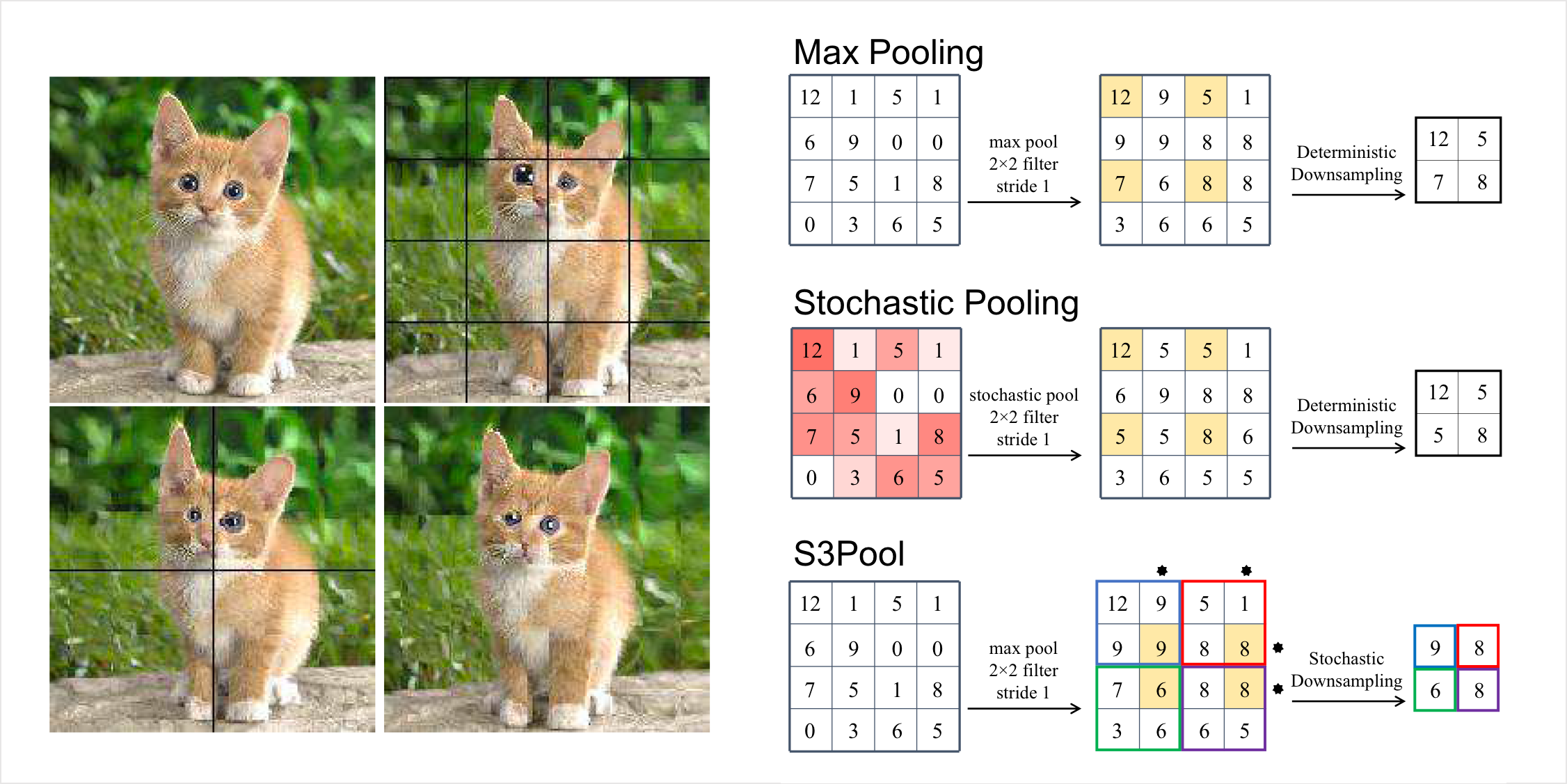 S3pool - Pooling with stochastic spatial sampling
S3pool - Pooling with stochastic spatial sampling