
Dialog-based Interactive Image Retrieval
Overview
We proposed a novel type of dialog agent for the task of interactive image retrieval. Recently, there has been a rapid rise of research interest in visually grounded conversational agents, driven by the progress of deep learning techniques for both image and natural language understanding. A few interesting application scenarios have been explored by recent work, such as collaborative drawing, visual dialog and object guessing game. In this work, we tested the value of visually grounded dialog agents in a practical and yet challenging context. Specifially, we proposed a novel framework of image retrieval system which learns to seek natural and expressive dialog feedbacks from the user and iteratively refine the retrieval result.

Goal-oriented Training of Dialog Manager
When designing an interactive image retrieval system, deciding on which images to return to the users at each interaction round and how to aggregate the user feedback in a principled way are the essential problems to be addressed. The desired behavior of the retrieval system is to learn how to construct the optimal sequence of candidate images to obtain the most informative user feedbacks. Instead of specifying the rules for candidate image selection and feedback aggregation, we let the retrieval system (which we call dialog manager) automatically learn to optimize the retrieval objective, which is the ranking percentile of the target image. To the best of our knowledge, this is the first case of applying goal-oriented training to the context of interactive image retrieval.
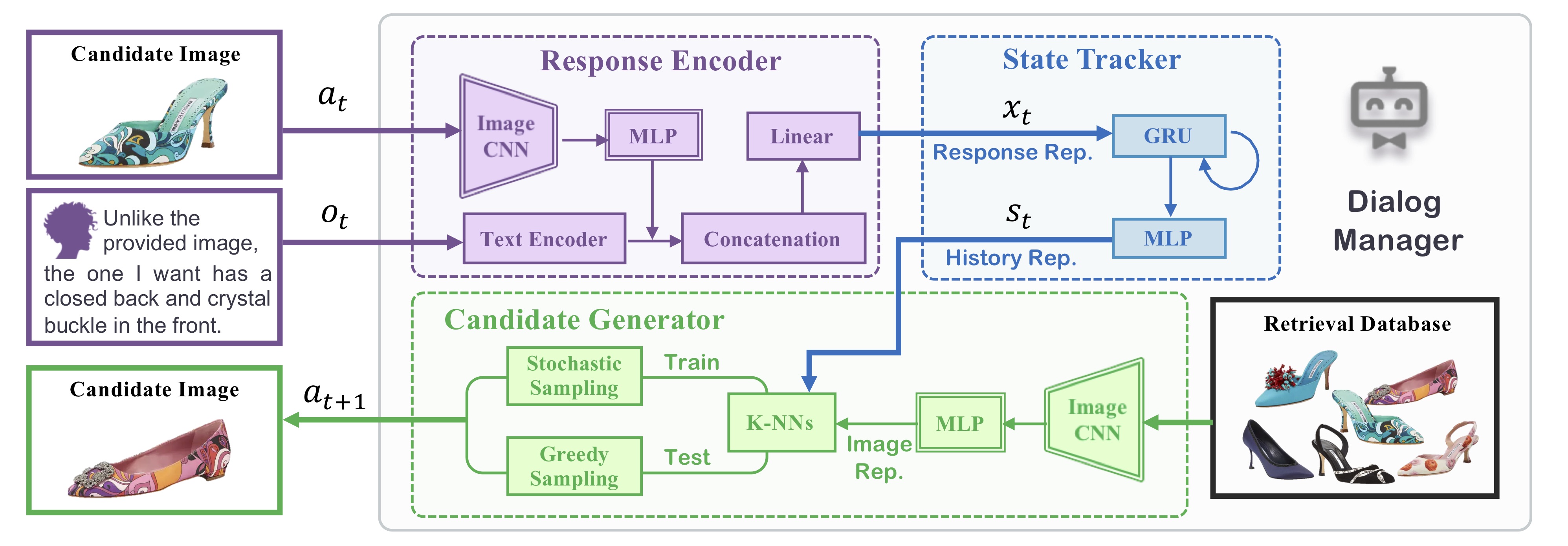
Below is the network architecture for our dialog manager, which consists of (1) a response encoder which embeds the information from the current dialog turn to a visual-semantic representation; (2) a state tracker which receives the response representation and combines it with the history information; and (3) a candidate image generator, which samples an image to return to the user based on distances between the history representation to each database image.
User Simulator based one Relative Image Captioning
One challenge remains in order to train the dialog management in a goal-oriended, end-to-end fashion, which is the lack of training data on user dialogs. The natural approach is to train the dialog manager in an online way with human annotator in the loop. However, this procedure is prohibitively slow and expensive. It takes about one minute to collect one set of dialog with 10 rounds of interactions. So 120k sets of training dialogs requires 2k hours of annotation effort.
To this end, we employed model-based reinforcement learning for training the dialog manager. The user model is based on a novel computer vision task: relative image captioning, which learns to describe prominant visual differences between two images using natural language. The trained relative captioner serves as a proxy of human annotators and allows for efficient training of the dialog manager without costly annotation. We collected a dataset for relative image captioning and trained a show-attend-tell based captioner. We found that although there is a difference between the generated descriptions and human provided descriptions, for the most cases, relative captioner is able to provide reasonable descriptions for any given pair of shoe images:

Code and Dataset
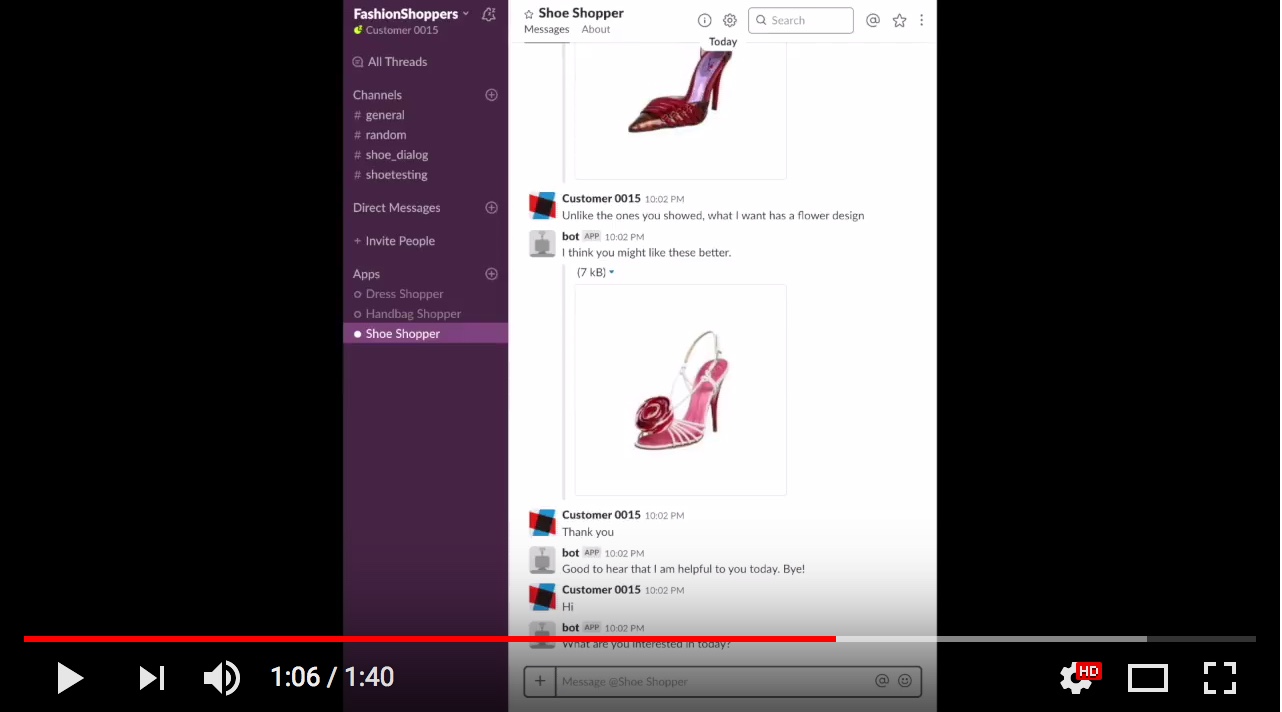
Below is a video showcasing an user interacting with the dialog manager. Code and dataset are available here.
Reference
[1] Xiaoxiao Guo*, Hui Wu*, Yu Cheng, Steven Rennie, and Rogerio Schmidt Feris. "Dialog-based Interactive Image Retrieval." NIPS 2018.(* equal contribution)